ASN.1 is the acronym for Abstract Syntax Notation One, a language for describing
structured information; typically, information intended to be conveyed across some
interface or communication medium. ASN.1 has been standardised internationally. It is
widely used in the specification of communication protocols.
Prior to ASN.1, information to be conveyed in communication protocols was typically
specified by ascribing meanings to particular bits and bytes in protocol messages, much as
programmers, before the advent of high level languages, had to deal with the bits and
bytes of storage layout.
With ASN.1, the protocol designer can view and describe the relevant information and
its structure at a high level and need not be unduly concerned with how it is represented
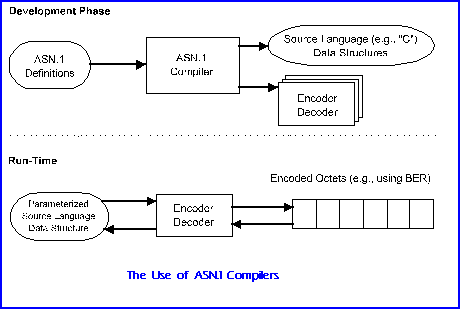
while in transit .Compilers can provide run-time code to convert an instance of user or
protocol information to bits on the line.
ASN.1 comes into its own when the information being described is complex. This is because the language allows arbitrarily complex structures to be built up in a uniform way from simpler components, and ultimately from a few simple information types. ASN.1 is, in effect, a data definition language, allowing a designer to define the parameters in a protocol data unit without concern as to how they are encoded for transmission. He merely states a need for an Integer followed by text, followed by a floating point number, etc. They can be named and tagged such that two integers can be differentiated as meaning "filesize" or "record number", for example.
Given any ASN.1 description of a message, a representation can be derived mechanically
by applying a set of encoding rules. While many such sets could be imagined, initially
only a single set, the Basic Encoding Rules (BER), were standardised as a companion
standard to ASN.1 itself. Subsequently two subsets of the basic rules have been approved.
These are the Canonical and the Distinguished Encoding Rules. These are exact subsets of
the BER, but where it has choices the subsets restrict these to a single possible
encoding. In addition, a completely new set of encoding rules has been devised in response
to the criticism that BER is highly inefficient, e.g., three bytes to encode a boolean.
These are called the packed encoding rules
The "One" was added to the ASN name by ISO to leave open the future
possibility of a better language for expressing abstract syntaxes. However, an
"ASN.2", should it ever be considered necessary, will have to be significantly
more powerful than ASN.1 to be worth inventing.
To illustrate the concept of abstract syntax consider, for example, ameteorological
station, which reports on the prevailing atmospheric conditions to a monitoring centre. At
the monitoring centre, the information is input to a weather forecasting program.
With abstract syntax the concern is solely with the information conveyed between the
application program running in the computer at the weather station and the application
program running in the computer at the monitoring centre.
For different reasons, both programs need to "know" what information is
included in a report. The application in the weather station needs to know so that it can
create reports from the appropriate sensor readings. The application in the centre needs
to know because it must be able to analyse reports and make weather forecasts.
This knowledge, which is essential for the programs to be written, is that of the
abstractsyntax; the set of all possible (distinct) reports. The designer of the abstract
syntax also defines the meaning of each possible report, and this allows the developers of
the programs at each end to implement the appropriate actions.
It would be very unusual for a designer to define the abstract syntax of a message type
by explicitly listing all possible messages. This is because any realistic message type
will allow an infinite number of distinct possibilities, integer as a simple example of
this. Instead, the abstract syntax will generally be structured. The set of possible
messages and their meanings can then be inferred from knowledge of the possibilities for
each of the components of the structure.
ASN.1 notation is recognisable as a high level definition language. It is constructed
in modules with unique identifiers. There are over 20 built data types such as:
| Simple data types | Character strings | Useful Types |
| BOOLEAN | NumericString | GeneralizedTime |
| INTEGER | PrintableString | UTCTime |
| ENUMERATED | TeletexString | EXTERNAL |
| REAL | IA5String | ObjectDescriptor |
| BIT STRING | GraphicString | |
| OCTET STRING | GeneralString | |
| NULL |
Arbitrarily complex structures can be built up from these data types using constructors
such as:
and other useful modifiers such as: OPTIONAL and IMPLICIT
Using ASN.1, the weather report abstract syntax could be expressed as follows:
WeatherReport ::=SEQUENCE
{
stationNumber INTEGER (1..99999),
timeOfReport UTCTime
pressure INTEGER (850..1100)
temperature INTEGER (-100..60)
humidity INTEGER (0..100)
windVelocity INTEGER (0..500)
windDirection INTEGER (0..48)
}
A simple protocol data unit might take the form
File-Open-Request ::=SEQUENCE {
filename [0] INTEGER
password [1] Password OPTIONAL
mode BITSTRING {read o,
write 1'
delete 2}
Password ::=CHOICE {OCTETSTRING, PrintableString}
Earlier standards such as ASCII and EBCDIC specified both the abstract syntax (the
letter A) and the encoding, or transfer syntax, (hexadecimal 21 or 41). ASN.1 separates
these two concepts, such that at connect time you can chose to encode the data. Youcan
chose an encoding which is efficient on the line or reliable or easy to decode. The first
defined for ASN.1 was the Basic Encoding Rules (BER)
The BER allow the automatic derivation of a transfer syntax for every abstract syntax
defined using ASN.1. Transfer syntaxes produced by application of the BER can be used over
any communications medium which allows the transfer of strings of octets. The encoding
rules approach to transfer syntax definition results in considerable saving of effort for
application protocol designers. This is particularly pronounced where the messages
involved are complex. Perhaps even more important than the savings to the designers are
the potential savings to implementors, through the ability to develop general-purpose
run-time support. Thus, for example, encoding and decoding subroutines can be developed
once and then used in a wide range of applications.
A set of encoding rule can only be developed in the context of an agreed set ofconcepts
such as those provided by ASN.1. For example, the concepts required in designing the
weather report abstract syntax included the ability to create a message from a sequence of
fields, and the concepts of integer and whole number (restricted to certain ranges).
As the structure of ASN.1 is hierarchical, the basic encoding rules follow this
structure. They operate on a Tag, Length Value (TLV) scheme. This is actually known in
ASN.1 as Identifier, Length, Contents. (ILC). The structure is therefore recursive such
that the contents can be a series of ILCs. This bottoms out with genuine contents such as
a text string or an integer.
The fundamental concepts of ASN.1 are the inter-related notions of type and value. A type is a (non-empty) set of values, and represents a potential for conveying information. Only values are actually conveyed, but their type governs the domain of possibilities. It is by selecting one particular value of the type, rather than the others, that the sender of a message conveys information. The type may have only a
few values, and therefore be capable of conveying only a few distinctions. An example
of such a type is Boolean, which has only the two values true and false, with nothing in
between. On the other hand, some types, such as Integer and Real, have an infinite number
of values and can thus express arbitrarily fine distinctions.
An abstract syntax can be defined as a type, normally a structured type. Its values are
precisely the set of valid messages under that abstract syntax. Should the messages be
structured, as they commonly are, into fields, then the various fields themselves are
defined as types. The values of such a type, in turn, are the set of permitted contents of
that field.
A type is a subtype of another, its parent (type), if its values are a subset of those
of the parent. Thus, for example, a type "whole number"" whose values are
the non-negative integers, could be defined as a subtype of Integer. (ASN.1 does not
provide such a type, but one could be defined by the user if needed). Another example
would be to define the YEAR as the twelve months and the subtype SPRING as March, April
and May.
A type may be simple or structured. The simple types are the basic building blocks of
ASN.1, and include types like Boolean and integer. A simple type will generally be used to
describe a single aspect of something. A structured type, on the other hand, is defined in
terms of other types - its components - and its values are made up of values of the
component types. Each of these components may itself be simple or structured, and this
nesting can proceed to an arbitrary depth, to suite the needs of the application. All
structured types are ultimately defined in terms of simple types.
ASN.1 makes available to the abstract syntax designer a number of simple types, as well
as techniques for defining structured types and subtypes. The designer employs these types
by using the type notation which ASN.1 provides for each such type. ASN.1 also provides
value notation which allows arbitrary values of these types to be written down.
Any type ( or indeed value) which can be written down can be given a name by which it
can be referenced. This allows users to define and name types and values that are useful
within some enterprise or sphere of interest. These defined types (or defined values) can
than be made available for use by others. The defined types within some enterprise can be
seen as supplementing the built-in types - those provided directly by ASN.1. ASN.1 also
provides a small number of useful types, types which have been defined in terms of the
built-in types but which are potentially of use across a wide range of enterprises.
A type is defined by means of a type assignment, and a value is defined by a value
assignment. A type assignment has three syntactic components: the type reference (the name
being allocated to the new type); the symbol "::=", which can be read as
"is defined as"; and the appropriate type notation. For example:
WeatherReport ::=SEQUENCE
{
stationNumber INTEGER (1..99999),
timeOfReport UTCTime
pressure INTEGER (850..1100)
temperature INTEGER (-100..60)
humidity INTEGER (0..100)
windVelocity INTEGER (0..500)
windDirection INTEGER (0..48)
}
defines a type called WeatherReport. Everything following the "::="
constitutes valid type notation (for a structured type which comprises a sequence of
simple and structured types).
A value assignment is similar, but has an additional syntactic component: the type to
which the value belongs. This appears between the value reference (the name being
allocated to the value), and the "::=". For example:
sampleReport WeatherReport::=SEQUENCE
{
stationNumber 73290
timeOfReport "900102125703Z",
pressure 1056,
temperature -3,
humidity 26,
windVelocity 15,
windDirection 0
}
defines a value of type WeatherReport called sampleReport. The characters after the
"::=" constitute valid notation for a value of WeatherReport.
The definition of types and values is almost the only thing that ASN.1 users do. Of
these two, the definition of types predominates. This is because an abstract syntax itself
is a type, as are its components, and their components, and so on. In a specification, it
is the types, the sets of possible values, which are most significant. Individual values
only appear as examples and defaults. Consider how much more useful in a specification is
the type INTEGER than the particular value 314 (or any other integer value for that
matter). Conversely, in instances of communication it is values which are significant.
Frequently the designer intends only some subset of the values of an ASN.1 type to be
valid in some situation. For instance, in conveying a measure of humidity as a percentage,
only numbers in the range 0 to 100 are valid, or when conveying a postal code only strings
with certain characters and whose length falls within a certain range are to be permitted.
Perhaps when some protocol message is used in a certain context, the optional checksum
field is to be absent.
These are all examples of constraints which can be expressed by defining a subtype of a
suitable parent type. This is done by appending to the notation for the parent a suitable
subtype specification. The result is itself a type and can be used anywhere a type is
allowed. (Thus a subtype specification can also be applied to a subtype, in which case it
may serve to further reduce the set of values).
A subtype specification consists of one or more subtype value sets, separated by
"|" (pronounced "or"). The whole list is in round brackets(()).
For example in:
Weekend ::= DaysOfTheWeek (saturday | sunday)
the type Weekend is defined by appending a subtype specification to a parent type
DaysOfThe Week. The subtype specification (the expression in round brackets) defines which
of the values of DaysOfTheWeek are also to be values of Weekend.
There are six different value set notations. Two of these are applicable to all parent
types, others to only certain parent types.
The value set notations that are applicable to all parent types are single value and
contained subtype. The former notation is simply some value of the a parent type, the
resulting value set consisting of that value alone. Examples of this are
"saturday" and "sunday" above, each of which is a single value of
DaysOfTheWeek. The contained subtype notation comprises the keyword INCLUDES, followed by
some other subtype of the same parent type, and denotes the value set consisting of all
the values in that subtype.
For example, given:
LongWeekend ::= DaysOfTheWeek
(INCLUDES Weekend | monday)
the type LongWeekend includes the three values saturday, sunday, and monday, the union
of the value sets used in its definition
Each value set defines some subset of the values of the parent type. The resulting
subtype has the values in the union of these subsets, which must be non-empty..
The value range notation can be used to subtype any type whose values are ordered (for
example, the integer type). It involves specifying the lower and upper bounds of the
range.
A size range can be included for any type whose values have a defined size (for
example, the bit string type). Here the value set includes all of the values whose size,
measured in the appropriate units, is within the designated range.
An alphabet limitation can be applied only to character string types and allows only
the values formed from some subset of the characters.
Finally, inner subtyping can be employed to define value sets of structured types (for
example, set and set-of-types). Here the value set includes all those values whose
component values meet certain constraints.
Several categories of object in ASN.1 have names by which they can be referenced.We
have actually met examples of each of these kinds of name above, as follows:
| type reference: | WeatherReport |
| value reference: | sampleReport |
| identifier: | humidity |
It is very important that names are chosen, as in these examples, to have significance
to the human reader. Indeed, if names are chosen correctly (and appropriate layout
conventions followed), then the essence of some piece of ASN.1 can often be grasped, even
by someone unskilled in the language.
All names in ASN.1 are character strings drawn from the same set of characters, namely:
| upper-case letters: | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| lower-case letters: | abcdefghijklmnopqrstuvwxyz |
| decimal digits: | 0123456789 |
| hyphen: | - |
The first character in a name must be a letter. The case of the letters in a name is
significant, so that "borders" and "Borders" are different names. In
fact the case of the initial letter is of special significance, as type references (and
also module references, see below) must start with an upper-case letter, while value
references and identifiers must start with a lower-case letter. It is not a good idea,
however, to use two or more names which differ only by the case of some of their letters.
The names chosen by users must be chosen so as to avoid clashing with the reserved
words of ASN.1 (which include most of the keywords of the language). Since the keywords
are generally in upper-case, the use of lower-case letters in names makes it easy to
adhere to this, and also generally makes the names more readable. There is no upper limit
on the length of names, and this allows the use of an appropriate phrase as the name of an
object.
Examples of legal (and probably appropriate) names are:
| UnformattedPostalAddress |
| Access-control-list |
| ACL |
| Temperature |
| MverifyPDU |
| recordLow |
| ib-g3facsimile-non-basic-parameters |
The first few of these examples are valid for use as type references, the others as
identifiers or value references.
Notice that two different conventions are used in these examples for forming multi-word
names, since spaces are not valid in names and thus can not be used to separate the
individual works.
As with any modern programming language ASN.1 is modular. A module is a named
collection of definitions of types and values (and macros - see next section). A module
normally groups together a set of related definitions, such as all those used in defining
some abstract syntax. However, the basis for grouping definitions into modules is entirely
in the hands of the designer, who could put all definitions into one module, or organise
them into several modules, according to taste.
Within a module, definitions can appear in any order, with none of the restrictions
sometimes found in programming languages, such as "define before use". It is up
to the designer to organise the definitions to make the result most understandable to the
reader.
All types and values defined in a single module must be allocated distinct references,
and within the module such a reference unambiguously identifies the applicable type or
value.
A module consists of, in order: the module identifier; the keyword DEFINITIONS;
optionally, the tag style default; the symbol "::="; the module body. The module
body consists of the exports and imports statements, if any, followed by the type and
value assignments, all enclosed between BEGIN and END.
An example of a module is as follows. The component parts - what should be inside the
second and third curly brackets - are omitted, but see Section E.2.1 for what would be
entered.
WeatherReporting {2 6 6 247 1} DEFINITIONS ::=
BEGIN
WeatherReport ::= SEQUENCE { ..... }
sampleReport WeatherReport ::= { .....}
END
The module identifier (which precedes the keyword DEFINITIONS) constitutes the complete
and unambiguous identification of the module. It consists of two components, the first a
module reference and the second an object identifier value; in the example they are
WeatherReporting and {2 6 6 247 1} respectively.
A module reference is the same (syntactically) as a type reference. The module
reference should be chosen so as to be suggestive of the contents of the module in some
way, and, if possible, unambiguous.
The other component, the object identifier value, is a globally unique identification
for the module, made up of a sequence of non-negative numbers.
Object Identifier was originally developed as part of the ASN.1 standard, but is now
ubiquitous. It is essential in any global network as it is a unique naming space. It
allows any communications object to be uniquely identified. It is a hierarchical naming
space, with the authority to specify Object Identifiers being passed down the hierarchy.
Thus an enterprise may register itself and then sub-allocate number space to its branches
or subsidiaries.
Specifically Object Identifiers are becoming used more and more to identify Managed
Objects whether these are SMTP or ISO Managed Objects. This allows for global network
management on the basis that every type of object has a unique identification.
While the object identifier value is optional, this is largely for backwards
compatibility reasons, because it was not present in the first version of ASN.1. In
practice it is not a good idea to omit it.
ASN.1 provides a mechanism whereby users can extend the notation for their own use, or
for use by others. This allows the designer to extend the language to define a new
"object" such as a modem or a switch. These have "normal" ASN.1
properties and additional properties such as parenthood and physical location. For example
an "asynchronous modem" may have "generic modem" as a parent. It
inherits properties from the parent. A modem may physically be in the same rack as others
and we have a second hierarchy of physical location. ASN.1 itself can be used to define
properties such as:
modem ::= SEQUENCE {
speed INTEGER
modulation IA5 String
manufacturer IA5 String }
but the additional features require the MACRO extensions to specify them. This
generates a form of "template" for the designer to fill in.
A user extending the notation does so by defining one or more macros, using the macro
definition notation (MDN). Each macro has a macro reference (like a type reference
except that all letters, not just the first, must be in upper-case), and grammars for type
and value notation. These grammars are defined by the macro designer using Baccus Naur
Format (BNF).
A macro definition can be imported and exported by means of its macroreference, just as
with type and value definitions.
The macro capability provides fairly powerful abilities for the definition of new type
and value notation within ASN.1 modules, with the full power of BNF available to the
designer, as well as some powerful built-in symbols, such as for types and values.
The macro defines a kind of definition form or template for a concept which is more
complex than just an ASN.1 type and value. In fact it is an assemblage of related types
and values, related through being aspects of the same operation.
Such a form or template could clearly have been defined by means outside of ASN.1.
However, because many or all of the aspects of such a concept are specified using ASN.1,
it proves very convenient to be able to include the definition within an ASN.1, module
along with the definitions of the types and values involved. Furthermore, because the use
of macros results in ASN.1 types and values, they can be given reference names, can be
included in modules, and can be imported and exported using all of the same mechanisms
already provided in ASN.1.
The macro corresponds to some concept, more complex than a data type, of which users
can define instances. The type notation defines the form or template, with all of the
appropriate degrees of freedom provided. The value notation is almost always an integer or
object identifier value which is the delivered value, and which constitutes the
"run-time" identification of the instance.
When the encoding rules were separated from the notation, they were dubbed the Basic
Encoding Rules (BER), with the idea that there might be justification for defining
different sets of encoding rules. Such encoding rules would not just be different for the
sake of being different, but would be designed to meet some functional requirement, such
as optimising compactness of encoding at the expense of computational overhead, or vice
versa.
Thus additional rules were defined in subsequent revisions. These are in two flavours.
The first, Canonical and Distinguished Encoding Rules, are designed to reduce options for
encoding and thus reduce decoding computational overhead. The second are exactly targeted
at reducing line overhead. They provide line efficiency at the cost of processing
overhead.
 It is worth noting
that a clear advantage of the use of encoding rules such as the BER rather than
hand-crafting transfer syntaxes is that application designers do not need to be familiar
with their details; indeed neither do most implementors. This is analogous with the way
that programmers using high-level languages do not have to know in detail how data
structures are held in memory. However in both cases it helps to have a general awareness,
if for no other reason than to know how "expensive" various constructs are.
It is worth noting
that a clear advantage of the use of encoding rules such as the BER rather than
hand-crafting transfer syntaxes is that application designers do not need to be familiar
with their details; indeed neither do most implementors. This is analogous with the way
that programmers using high-level languages do not have to know in detail how data
structures are held in memory. However in both cases it helps to have a general awareness,
if for no other reason than to know how "expensive" various constructs are.
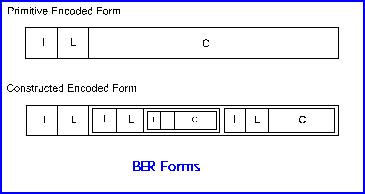
The BER generate encodings which are of a class known as type - length - value (TLV),
so called because the basis of encoding is a structure made up of those three parts. Many
protocols employ encoding schemes of this general kind. However, few apply the idea so
consistently as the BER.
With BER, the encoding of every data value in an abstract syntax, whether an entire PDU
or some component of it, is constructed in TLV style. The three parts are actually termed
identifier (I), length (L) and contents (C).
The identifier conveys three pieces of information: the tag class of the data
value being conveyed; the tag number, the formof the encoding - whether it is primitive
or constructed.
The length (together with the form) allows the end of the contents to be found.
The receiving system need not understand the tag to find the end of the contents, and this
allows an encoding to be skipped if it cannot (yet) be decoded.
The contents is the substance of the encoding, conveying the actual value. When
the form of the encoding is primitive, the contents is simply a series of octets (zero or
more) and when the form is constructed, the contents is a series of nested encodings, each
itself having identifier, length and contents.
This nesting can be as deep or as shallow as needed; its primary purpose is to convey
values which have components which themselves have components, and so on, to any depth.
Nesting stops either with a primitive encoding, or with a constructed encoding with empty
contents. Each part of the encoding (and therefore also the encoding as a whole) is an
integral number of octets.
ASN.1 is at the core of open systems applications today and has been revised to include
a replacement for the MACRO mechanism and additional encoding rules. The main parts of the
standard are summarized below. ASN.1 is now ubiquitous and even used by the Internet
network management protocol, SNMP.
| X.680 | ISO/IEC 8824-1 | Basic ASN.1 Notation |
| X.681 | ISO/IEC 8824-2 | Information Objects Specification |
| X.682 | ISO/IEC 8824-3 | Constraint Specification |
| X.683 | ISO/IEC 8824-4 | Parameterization |
| X.690 | ISO/IEC 8825-1 | Basic, Canonical and Distinguished Encoding Rules |
| X.691 | SO/IEC 8825-2 | Packed Encoding Rules |
| Amendment 1 | Rules for Extensibility |
[This chapter is based on extracts from Doug Steedman's book Abstract Syntax
Notation One (ASN.1) - The Tutorial and Reference, published by Technology Appraisals]